
DNA101
Page Contents
What is DNA?

DNA stands for Deoxyribonucleic Acid, which is a literal description of its chemical composition.
It is the code that allows Earth’s complex lifeforms to recreate themselves generation after generation.
DNA is a four letter code (A, C, T, G) made up of two homologous strands.
A always binds with T.
C always binds with G.
The reliable nature of this binding allows a strand of DNA to be easily copied by an enzyme known as DNA polymerase.
DNA polymerase unsticks the strands from one another and uses each as a template for making two new strands. This process differs between prokaryotes and eukaryotes, but the purpose is the same: keep recreating the lifeform so that the DNA sequence can survive. From the perspective of your DNA, you’re just another stepping stone on the road to immortality.
DNA doesn’t just code for its own replication, it also codes for the production of everything in the cell. The strand is unstuck and an enzyme known as RNA Polymerase transcribes the code into RNA. The RNA is packaged and moved to a Ribosome, which uses the RNA code to produce a Protein. This is known as the “Central Dogma of Molecular Biology”.

The Central Dogma of Molecular Biology.
QUICK HISTORY LESSON!
Our knowledge of DNA goes back a long way! Mendel described the role of ‘factors’ in pea plants in his 1865 publication and Friedrich Miescher purified DNA in 1869. It wasn’t until 1944 that Oswald Avery connected the two, realising that it was DNA rather than proteins that held the code of life.
In 1945 George Beadle first described the one gene = one enzyme theory that would go on to dominate gene theory for the next few decades. This theory would prove to be a useful rule of thumb… but it would go out of fashion once we realised the sheer number of exceptions that existed in nature. Despite this, it helped illustrate a clear mechanistic link between the code of DNA and the synthesis of proteins.
The ultimate structure of DNA wouldn’t be discovered until 1952 when Rosalind Franklin helped Watson and Crick photograph DNA using X-ray Crystallography.
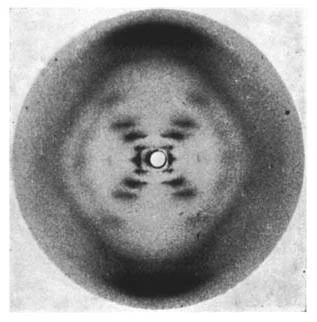
The legendary “Photo 51” that led to the discovery of the Double Helix. Source: http://scripts.iucr.org/cgi-bin/paper?S0365110X53001939
The double helix structure with two homologous strands provided the unique combination of stability and replicability that scientists expected from the molecule that manages to keep the code of life stable across millions of generations.
While we stand on the shoulders of these giants, this guide will now focus on the modern knowledge borne from their discoveries rather than obsessing over each of their models in detail. It is the fate of we scientists to be relegated to the status of a historical footnote, lest our out-of-date theories clash with contemporary doctrine. Please go read their publications if you are interested in learning more :)
END OF HISTORY LESSON
DNA copies itself in multiple ways, depending on the host type and the role of the cells. Large, multicellular, eukaryotic organisms such as ourselves replicate DNA during the processes of Mitosis and Meiosis;
Mitosis - the reproduction of somatic cells [body cells] to fight against ageing and entropy.
Meiosis - the creation of gametes [sex cells] to allow for the creation of offspring through reproduction.
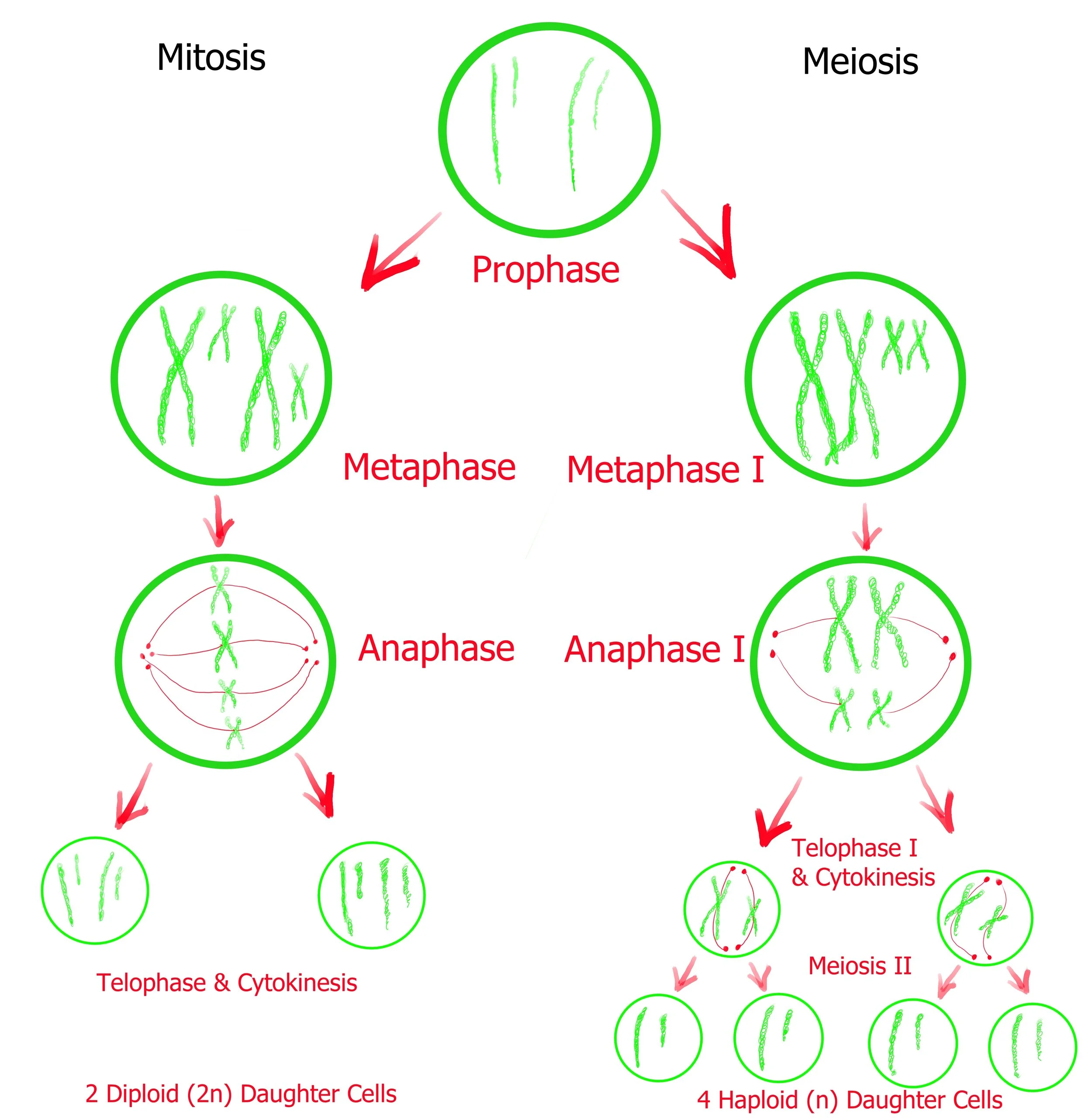
Depending on their location in the organism, Eukaryotic cells (such as your own) will perform either Mitosis or Meiosis. Mitosis will produce more somatic (body) cells and meiosis will produce gamete (sex) cells. This diagram helps illustrate the similarities between the two processes - but keep in mind that Meiosis II has more steps than this diagram is letting on. Keep reading for more details on each…
The reproduction of DNA within prokaryotic, single-celled organisms occurs during a process known as binary fission. During binary fission the cell makes a copy of all the DNA before splitting down the middle to form two new daughter cells.

Plasmids are extra-genomic code that carry their own origin of replication (pictured in red). The origin of replication is where the replication of DNA begins.
DNA is not just critical for reproduction, it controls and regulates all protein synthesis. As you dive deeper into the functions of DNA, you’ll realise that it is through this capacity to control the protein content in the cell that DNA is able to become the ultimate regulator of its own reproduction. It might be a protein performing the regulation of DNA during a specific interaction, but the original source of that protein was the DNA itself. What came first, the proteins in the chicken or the DNA in the egg?
Now that you understand how DNA can persist across generations, it’s time to try to understand how it works. Perhaps more importantly, how it knows when to work. If all the DNA in your body started expressing itself simultaneously, you’d be dead in minutes. Instead an incredibly precise and delicate balance arises - how?

Hey look it’s you! Or someone that looks a lot like you…
Image credit: https://genomicmedicineuk.com/the-human-genome-structure-and-organization/
Let’s examine your genome for a moment… Every cell in your body (minus the blood/hair) has a nucleus. That nucleus contains 46 (23 for gametes) long chains of double-stranded DNA, each known as a chromosome. In total, these chromosomes contain just over 3 billion (3,088,286,401) base pairs.
This code is nearly-perfectly replicated across the ~3 trillion cells in your body. Yet despite being identical in sequence, the same set of chromosomes are able to perform a variety of functions by folding in different ways.
Chromosomal DNA is packaged around histones, proteins that efficiently pack and order the DNA so that it fits snugly within the nucleus. This packaging of DNA has a surprisingly large effect on protein expression, allowing the identical code in every cell to produce vastly different results.
Take a moment to admire all the varied systems in your body that are functioning to allow you to read this guide. From the eyes connected via an optical nerve to your brain, to the fingers that roll the mouse-wheel using muscles commanded by nerve signal - every variation in every cell emerges from the same genetic code. The only difference lies in how tightly it is folded.

How do you fit 46 ~5cm long strands inside a nucleus with a diameter of 5 µm? Wrap it reallllllyyyy tightly.
Unwound DNA is accessible and can be used for transcription and translation. Tightly wound DNA is prevented from performing its role and remains dormant until it is needed and subsequently unwound.
Sometimes the differentiation in gene expression is a necessary function of life, such as during your development as a foetus. From the moment sperm met egg, the pattern of DNA expression in your body followed a rigorous set of rules, a gene cascade that started with one omnipotent cell capable of becoming anything and ended with millions of unipotent cells can only perform a single function. Some of your cells remain multipotent to this day, working through mitosis to replenish & replace damaged or aging cells.

Every nucleus-containing cell in your body still contains the >3 billion base pairs contained in your original zygote (merged sperm + egg cell). The only difference is that the packing and organisation of the DNA has changed, whether it’s through inbuilt mechanisms or random changes introduced by the environment. While the field of genetics studies effects of DNA coding changes, epigenetics studies how non-coding changes can influence the end result of DNA expression. As technology and our understanding of molecular biology advances, it is hoped that these two fields will merge completely.
A big takeaway from this is that the genetic code for a liver cell can be found in a sample of skin cells. You don’t need to go digging deep to find DNA samples rich with information, the challenge is actually interpreting the data once you have it. Researchers who worked on the Human Genome Project speak of their hubris, believing that simply obtaining the genetic code would unlock the secrets of life and solve every genetic mystery. Instead they found a world of complexity beyond even their wildest dreams, a living computer coded as much by geometry as it was by chemistry.

Once the Human Genome Project was done, it was time to map the Human Proteome (all proteins and their interactions). Then maybe there might be some clarity as to how humans function… right? RIGHT? Image Credit: https://guardianlv.com/2014/05/proteome-map-nearly-complete/
The secret to progression in this field (as it so often is in science) is to strip out every possible variable except the experimental one. While learning and performing synthetic biology protocols, you will likely be focussed on the impact of changes to the genetic code and will attempt to rule out all epigenetic variables that could confound the link between cause and effect. This starts by choosing an organism that is well characterised and culturing it in a stable environment that won’t encourage any epigenetic changes. But it also requires a working model of DNA that doesn’t look like biochemical spaghetti.
This next section will teach you how to simplify your model of DNA in order to focus simply on genetic changes. But when we do this, it can become easy to always imagine it in 2D and forget that this code you are writing will be subjected to 3D folding and organisation within a complex cellular environment. When observing a 2D string of genetic code, remember to think: How might this look once it is folded and rubbing up against other DNA or proteins? Most of the time this will be an unnecessary mental exercise. But when things start going wrong and you’ve eliminated all the obvious variables from your 2D model - it’s time to start thinking in 3D again…
Mentally Picturing DNA
Modelling 3D intracellular fluid dynamics is a process beyond the capacity of even the brightest human minds. So, like all things in the universe too complex to understand, we use abstraction to simplify and add additional complexity only when absolutely necessary. Let’s strip out the complexity one step at a time until we have a model that we can work with for genetic design. This layered approach will give you an idea of the different ways you can picture DNA and you can work in reverse to add the complexity back in if your model fails to work as expected;
3 Degrees of Abstraction
(how to imagine DNA into a simple form)

O°: Native Model: Intracellular, actively functioning DNA
Sometimes you want to imagine DNA just how it is in nature. Unfortunately our tiny monkey brains which evolved for the purpose of explaining the location of nearby ripe fruit are unfit for such a complex task. Attempting to imagine this level of complexity is simply too much - you will never perfectly capture every possible variable in this morass of fluid dynamics. But that is okay! Even an imperfect model might allow you to diagnose a problem - especially if the more abstract DNA models have cut out the variable that has caused your problem.
What does this model show:
3D structure of DNA
Folding of DNA around native structures e.g. histones
Folding of DNA chromosome
Interaction of DNA chromosomes with each other
Protein interactions
RNA interactions
When you should use this model:
In-vivo models of DNA function
When attempting to understand/model complex, multi-step metabolic pathways
When attempting to diagnose a problem with a new synthetic circuit
When attempting to model potential challenges to a cell from introducing a synthetic circuit, e.g. loss of competitive edge
1°: Isolated DNA in Buffer (4D)
Let’s cut out a bunch of that complexity by removing all the competing intracellular machinery, and mentally picture the DNA purified into a buffered solution. This is a significantly simpler model to mentally visualise than the whole cell - and it is not so abstract that it doesn’t occur in reality. During the course of the protocols, you will regularly purify DNA and store it in a buffered solution. DNA won’t behave identically in this environment as it does inside the cell, but the buffer is designed to replicate intracellular pH. This allows the DNA to remain as close to its native state as possible. Unfortunately, this model is still too difficult to draw, since the 3D DNA structure is folded around itself so many times (4D folding).
What does this model show:
Purified DNA in a buffered solution
Double Helix structure (3D) coiled and folded around itself into a complex shape (4D).
Pure 3D structure isolated from the majority of cellular proteins and RNA. Histones and other tightly bound proteins may escape purification and are included in the model.
Requires mental visualisation or computer-aid, impossible to draw.
Histones are included in this image, but can be purified out as well. This will result in extremely tangled DNA, with the backbones chaotically interacting with one another. Equally complex to draw or imagine.
When you should use this model:
In-vitro models of DNA function
Models of how plasmid DNA will run on an Agarose Gel
Plasmid supercoiling, twist and writhe
Primer hairpin
Protein-DNA binding mechanisms
Effect of chelating agents
When deciding about further purification steps
2°: Double-Helix Model of DNA (3D)
The next degree of abstraction removes the 4-dimensional folding element, leaving just the 3D structure of the DNA chain. This model emphasises the importance of backbone-backbone interactions, but imagines that the DNA strand never folds back on itself. This model is abstract enough that it never occurs in practise, but can be useful for understanding certain implications of the helix structure - such as the binding of DNA dyes. Unlike the first two, this model is abstract enough that it can be hand-drawn or constructed as a 3D model from a chemistry set.
What does this model show:
A linear or circular DNA sequence (2D) organised into a simplified double-helix structure (3D) that doesn’t fold around itself.
Backbone interactions occur, with the major groove and minor groove appearing based upon the twist of the helix.
When you should use this model:
Models of dye intercalation
Experiments involving the DNA backbone
3°: Linear DNA Sequence (2D)
Finally, we come to our bread and butter as synthetic biologists - a DNA sequence stripped of all complexity and laid out like computer code. We’ll spend far more time with this model than any other, only diluting the abstraction with more complex variables when troubleshooting a design. It can be easy to get lost in the power of this model. You may feel like a god, capable of recoding life on the fly. Any time you’re struck by such hubris, you can remind yourself just how little you know by taking a step back and attempting to imagine your model with zero degrees of abstraction.
What does this model show:
2D structure of DNA. The strands have a ‘direction’ based upon the backbone structure, despite this structural element being simplified out of the model.
DNA sequences are always written 5’ > 3’. Assume sequences found online are written in this direction, unless specified otherwise.
The sequence of bases that make up the genetic code, written out in a linear fashion.
The complementary strand is often included in the reverse orientation (3’ > 5’), with lines between the strands to indicate complementary base-pairs
The backbone structure is essentially ignored, although 5’ or 3’ phosphates are occasionally included.
Can be handwritten, or even typed up on a word document as a string of letters. If it is double stranded DNA, a complementary homologous strand can be assumed.
You will use this model most of the time, especially during;
Experimental planning of the Polymerase Chain Reaction
Models of Melting Temperature (Tm)
Decisions about phosphorylation during ligation reactions
Models of primer binding
Agarose electrophoresis of linear DNA, DNA ladders, PCR reactions
Restriction Enzyme Digest simplified models
Models that involve the hydrogen bonds between base pairs

What is the structure of DNA?
The following section uses 2°-3° of abstraction. If we ignore the 4D folding, histones, cell junk, etc…
What are the raw components of DNA?
How do they assemble into a chain?
DNA is just a long chain made up of 4 repeating units known as Nucleotides. Each nucleotide contains a phosphate, a ribose sugar and a nitrogenous base (A, C, T or G). The phosphate and sugar remain constant, while the attached nitrogenous base gives the molecule its unique nature. The important nitrogenous bases can be divided into two groups, based upon the structure of their central chemical rings;
Purines
Adenine (A)
Guanine (G)
Pyrimidines
Cytosine (C)
Thymine (T)
Uracil (U) - replaces T in RNA sequences.

We often use these letters (A, C, T, G and U) to describe the nucleotide as a whole, often as part of a long chain of DNA.
The next step is easier if we number the individual atoms in the Purines/Pyrimidines, then do the same for the carbons in deoxyribose (the dash is read as ‘prime’ - i.e. 1’ = 1-prime, 2’ = 2-prime, etc).
We can then observe the three reaction locations crucial to the assembly of DNA. The 1’ carbon links to the (1 or 9) nitrogen of the nucleic acid, while the 5’ and 3’ carbons are each linked to a phosphate to form the backbone.
This backbone asymmetry is what gives DNA its unique directionality. Operations that start at the 5’ end of a DNA sequence and work towards the 3’ end have a forward mechanism. Operations that start at the 3’ end and work towards the 5’ end have a reverse mechanism.

The assembly of nucleotides into a strand with a contiguous sugar-phosphate backbone will not spontaneously occur - it is an energy intensive dehydration polymerisation reaction. This energy is generally provided in the form of a high energy phosphate bond, often from the ATP molecule. DNA Ligase breaks the energy rich phosphate bond in ATP in order to gain the energy necessary to repair breaks in the DNA backbone. When assembling DNA using PCR, you will build your new DNA chains with a polymerase that utilises nucleotide-triphosphates (nucleoside bound to three phosphates). These extra phosphates are used by DNA polymerase as an energy source to build new strands of DNA.
Each nucleotide is bound in a strong covalent bond to adjacent nucleotides in the chain, resulting in a contiguous backbone. Meanwhile the same is true for the backbone of the complementary strand.

The complementary strand for this section would have the code TT. Also note that the dotted lines will have likely have phosphates attached, continuing the chain in both directions.
Between the strands we can see the hydrogen bonds that hold base-pairs together. These are the weakest bonds in the chemical structure, but that’s okay! This weakness is critical to the function of DNA. When protein production or DNA reproduction is required, these hydrogen bonds (two bonds for A-T, three bonds for C-G) can be selectively broken by an enzyme in order to gain access to the code within. It takes more energy to break the three hydrogen bonds in C-G than it does to break the two bonds in A-T, thus DNA with high GC content has a higher melting temperature (Tm). Once the enzyme is finished, the hydrogen bonds will selectively draw the homologous strands of DNA back together based upon whether two or three hydrogen bonds are available. The strands will anneal together without the need for additional energy input because this is their lowest energy state.

The breaking of hydrogen bonds within the DNA sequence is an everyday occurrence that is necessary for the operations of the cell. This doesn’t tend to cause problems because the sequence will almost always reanneal perfectly. On the other hand, breaks in the backbone are a rare and problematic occurrence that must be fixed immediately. If a double-stranded break occurs and there is a nearby homologous strand, then a perfect repair is possible (Homology Directed Repair [HDR]). This is one of the major reasons why you carry two sets of every chromosome in every one of your body cells. If there is no template for repair, the cell will fill in the blank spot with random noise - often resulting in a mutation event (Non-Homologous End-Joining [NHEJ]).
Now that we have the molecular structure of DNA, let’s combine it all into the simplest mental model - the 3° of abstraction, Two-Dimensional DNA Sequence;

Since the backbone and nucleotide structure are constant, we can write this sequence in simple text, reading 5’ > 3’, either strand could be the coding or template strand;

Left Strand: ATCGATCGA
Right Strand: TCGATCGAT
We can copy & paste this sequence into Snapgene, which will look like this >
Now we can see the sequence, read the sequence and potentially even modify the sequence!
More on that later. For now, let’s see just how much complexity your brain can handle. Let’s now try and add in the next layer of complexity with the 2° of abstraction, Three-Dimensional Double-Helix Model of DNA and see what additional insights might be gained;

As you can see, this starts to stretch the limit of a 2D drawing, obscuring the sequence from view. However rendering this model in a 3D computer engine can still produce a comprehensible visualisation.
However there are some elements here that were missed by our linear DNA sequence. Note the major groove and minor groove that appear as a natural consequence of the DNA structure. Enzymes or molecules (such as intercalating dyes) that interact with DNA tend to do so through the major groove, as there is additional space for access.
The next layer of complexity (1°: Four-Dimensional Isolated Native State DNA) introduces the fluid dynamics of the surrounding buffered solution as well as the possibility of interactions between distant sections of backbone. At this point, you’ll need a computer in order to accurately model what is occuring. You can build loose heuristics of understanding and make generalisations about what DNA actually looks like when purified into a buffer. We can use various forms of X-ray Crystallography and Electron Microscopy to visualise DNA and capture it for a moment in time. However these are only fragments of the complete picture. Solubilised DNA (DNA dissolved into a liquid) is constantly interacting with every local H2O molecule or Ca2+ ion that wanders nearby;

Finally we come to the ultimate layer of complexity. Zero degrees of abstraction, modelling real DNA inside a living organism. We’ve come a long way in our understanding of the role and functions of DNA across all walks of life. However a quantitative, descriptive model that can locate and describe the structure of all the DNA in a cell is far beyond even our most advanced algorithms or artificial intelligences. We can describe interactions, snapshots in time that help contribute to a larger picture of intracellular dynamics - but we’re yet to see the forest through the trees;

Wrap that DNA in a nucleus and surround it with proteins and cytoplasm and it is beyond our capacity to model in full. It’s also beyond my capacity to draw.
Where is DNA located? In what form?
Genomic DNA: The vast majority of DNA in most organisms will be in the genome. The location of the genome varies based upon the species in question;
Eukaryotes - Contain a membrane-bound nucleus. The genome is kept inside the nucleus, preventing the majority of proteins from interacting with it. The nuclear membrane itself plays a role in regulation, acting as a gatekeeper for chemical signals coming in and out. In most cases the eukaryotic genome is folded very specifically around histones to form chromosomes. Large regions of non-coding DNA (once called ‘junk’ DNA) play a role in genetic expression that is yet to be fully understood.
Genome size varies from 10 MB (million base pairs) to 149 GB (billion base pairs) - most of the largest genomes are a result of polyploidy (double or triple sets of homologous chromosomes).
e.g. Humans, mammals, squid, wheat, mosquitoes, bakers yeast, etc. All larger multicellular organisms are eukaryotic, as well as some single-celled organisms.
Prokaryotes - Do not contain an envelope-wrapped nucleus, instead the genome floats freely in the cytoplasm, often as a large circle of DNA.
Genome size varies 500 kb - 10 MB
e.g. E. coli, bacillus, blue-green-algae, etc.
Bacteriophages/Viruses - Some bacteriophages and Viruses have a DNA genome, held within their protein coat. Since they lack replication machinery, the role of the protein coat is to inject this genome into an appropriate host in order to hijack it. The genome is often highly compressed and nested.
Genome size varies 2 kb - 1 MB, with the largest variation in bacteriophages. Some phage genomes are larger than bacterial genomes, but the majority are smaller than 500 kb.
e.g. Caudovirales, Adenovirus, Herpesvirus.
Plasmid DNA: Plasmid DNA is extra-genomic code that contains instructions for its own replication, most often by prokaryotic hosts. These transient pieces of genetic information can enter the host, be used to express a new gene and then leave the host without integrating with the genome. Or they can force a new piece of genetic code into the genome at a selected or random point. Or they can become a necessary, extra-genomic piece of code that is passed on generation after generation. Plasmids are a powerful tool in the hands of a synthetic biologist.
DNA-Protein Complexes: Some enzymes require DNA in order to perform their function, such as the transcription factors that help control the production of proteins. This DNA doesn’t code for anything, instead it helps the protein bind correctly.
DNAzymes: Also known as DNA enzymes, Deoxyribozymes or catalytic DNA, these are DNA structures that help catalyse a reaction, in a similar way to regular protein enzymes.
The next section requires some knowledge of RNA and Proteins! If you find yourself getting lost, try making a start on these 101 guides and come back once you know the jargon;
RNA101
PROTEINS101
How does DNA work?
The vast variety of natural DNA functions necessitates that this chapter be shortened in scope. Thus we will focus on the two primary roles of DNA:
DNA codes for the synthesis of proteins
DNA is copied for reproduction
Between these two roles, DNA does most of the heavy lifting for the creation of life as we know it. Once you’ve completely grasped how DNA performs these tasks, feel free to investigate the more esoteric roles that DNA can play - for now, forget them. Focus instead on the unique differences in the function of DNA between prokaryotes and eukaryotes, reaching the same end-state goal by divergent means. Even proteins that are nominally the same, such as RNA polymerase or the Ribosome, exhibit significant structural differences between the domains of life. It is important to be able to grasp and recall these differences, lest you apply a eukaryotic-specific assumption to a bacterial cell.
DNA code can only run in one direction (5’>3’), but DNA is double-stranded - thus the code can actually run in both directions. The terms coding strand and template strand are arbitrarily applied based upon the protein of interest you are currently talking about. If you have two nested proteins, running in opposite directions - then both strands are coding and template strands… and I still have the gall to accuse chemistry of being confusing.
A DNA sequence can be broken into codons of three base-pairs each. Depending on where you start your codon sequence, you can read a double-stranded sequence of DNA in one of six frames. However, only frames that begin with a start codon will actually be transcribed - this is known as an Open Reading Frame (ORF). Other reading frames are ignored unless there is an additional start codon within the sequence. Sequences nested inside other sequences with alternate reading frames are quite common in nature. The ORF should also end in a stop codon (*).

While there are 6 possible reading frames, only the highlighted orange section is an Open Reading Frame. There is a stop codon, but it’s much later in the sequence.
After the DNA is transcribed into mRNA, it will bond to a ribosome which will build a protein based upon the encoded sequence. The ribosome will recruit tRNA-Amino-Acids that match the mRNA sequence (anticodons) and bond the amino acids together. The construction of these tRNA-Amino-Acid molecules by an aminoacyl-tRNA synthetase is external to the translation process, but a critical part of the story;

The mRNA-tRNA-Amino-Acid code is universal, according to the codon usage wheel below.

All species, whether eukaryotic or prokaryotic, will follow this universal RNA-AA code. However, there are 64 possible codons and only 20 amino acids. As a result, some species prefer to use one codon over another, leading their tRNA-activating-enzyme to make more of some tRNA-AA’s and less of others. This codon usage bias can be a bottleneck to you as a synthetic biologist if you don’t include codon optimisation in your Gblock design.
Protein Synthesis
Regardless of host type, protein synthesis involves three major steps;
Transcription
Translation
Folding
The location, modifications and enzymes involved vary across the domains of life - but the essential steps remain the same.
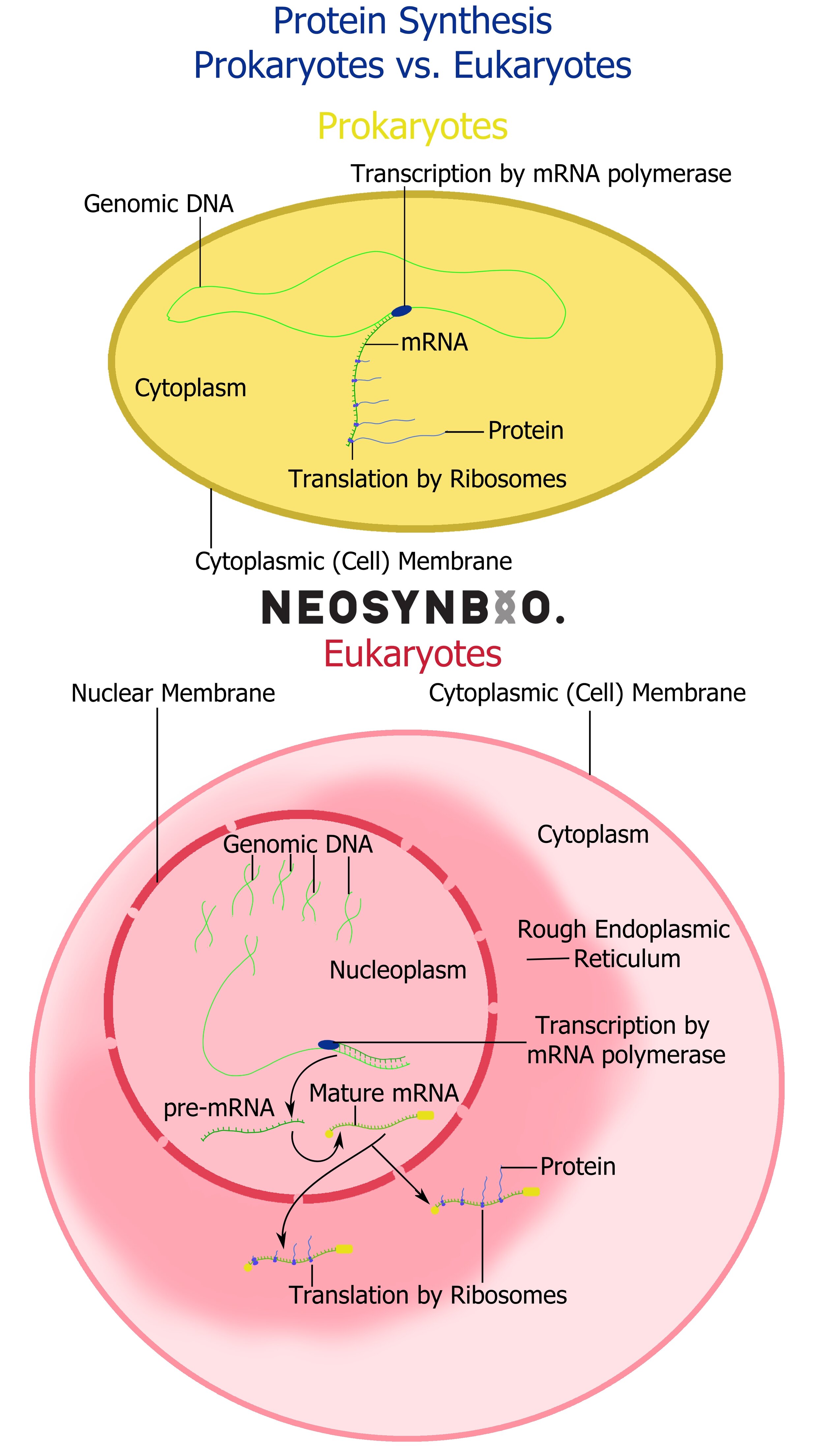
1) Transcription - Conversion of DNA code into messenger RNA (mRNA)
RNA polymerase binds to the DNA in the promoter region.
Additional proteins known as transcription factors may also join to aid in the reaction
This will be on the 5’ (upstream) side of a gene of interest.
RNA polymerase separates the two strands of DNA by breaking the complementary hydrogen bonds, creating a “transcription bubble”
RNA polymerase will move along the non-coding (template) strand, seeking out complementary base-pairs.
Each time RNA polymerase locates the correct nucleotide it will catalyse the sugar-phosphate backbone reaction, adding the nucleotide to the chain. This growing molecule is known as “messenger RNA” and it is identical to the coding strand
As the polymerase moves further along, the growing complementary RNA strand will detach from the DNA strand as the transcription bubble closes, allowing the template DNA strand to reanneal to the coding DNA strand.
When the RNA polymerase encounters the termination sequence it will detach, allowing the transcription bubble to close completely.
The newly synthesised mRNA strand will be processed differently depending on the host type.
Prokaryotes - The ribosomes are likely nearby and may begin translation immediately.
Eukaryotes - A 5’ cap is added to the 5’ end of the mRNA molecule (5’ capping) and a poly(A) tail is added to the 3’ end (3’ Polyadenylation). These help regulate the movement of the plasmid out of the nucleus and into the Rough Endoplasmic Reticulum, where ribosomes will begin to initiate transcription.

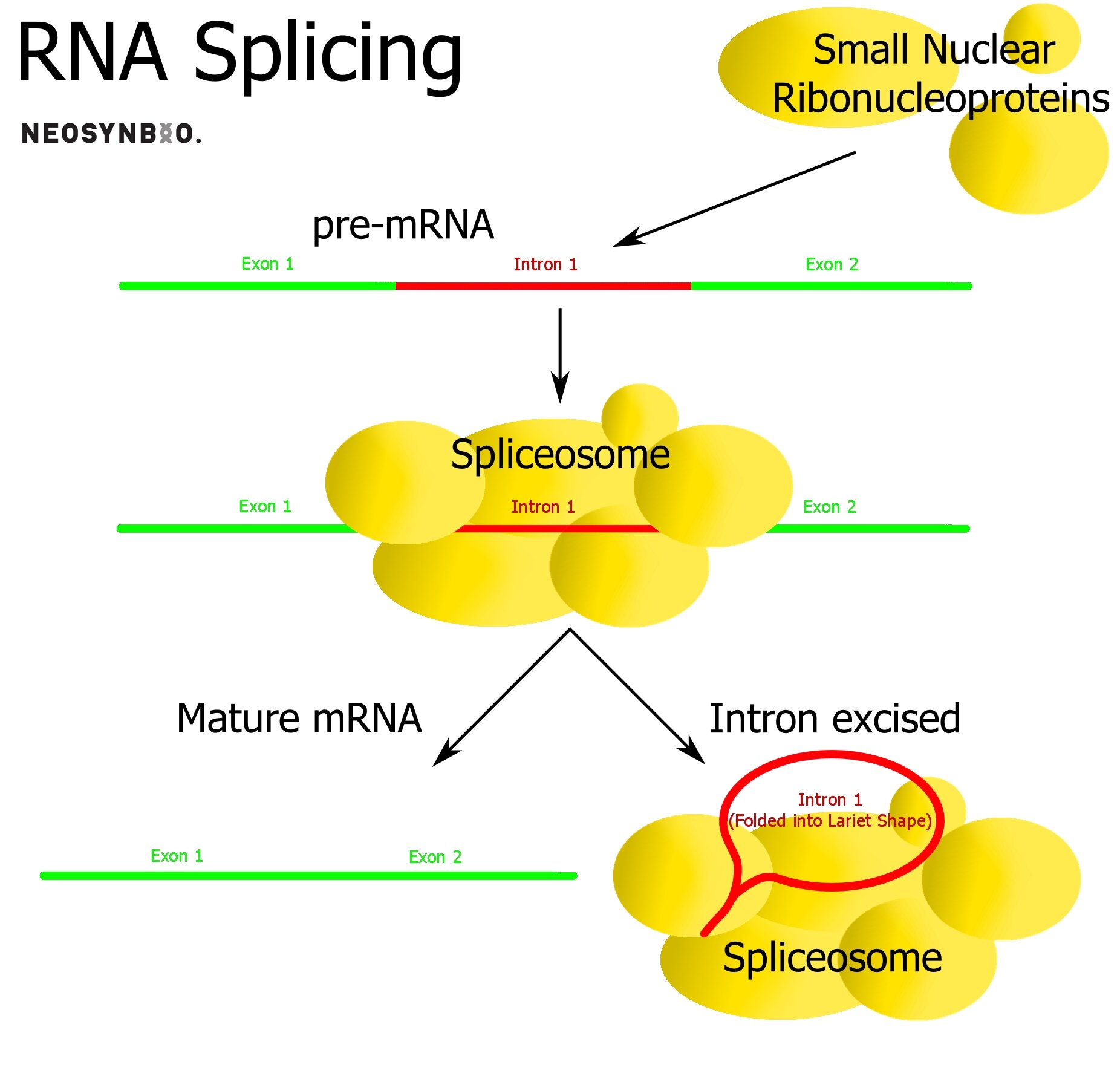
Eukaryotes Only: Intron removal
Within eukaryotic genes, there exist sequences that are transcribed but not translated - potentially playing a regulatory role that we do not fully understand. These introns self-excise, are removed by snRNA spliceosomes or removed by proteins depending on their function. The remaining fragments in the mRNA molecule are known as exons and it is these regions that will ultimately be translated.
The primary role of the intron/exon system is to provide the option of alternate splicing to the cell. A single protein sequence can be made into dozens of variants, simply by controlling which introns are excised and which remain as exons. Prokaryotes do not utilise exons/introns and they are rarer in simpler eukaryotes. In humans, up to 30% of our expressed protein is the result of genes varied by intron excision.
2) Translation - Conversion of mRNA into protein
Before we dive into translation, it’s time for a quick examination of the Ribosome. The Ribosome is made up of two parts that differ in size and functionality between the domains of life;

S refers to the Svedberg value, which relates to sedimentation in a centrifuge. It tells you a little about their size and almost nothing extra.
The roles and functions of the rRNA is complex enough to be beyond the scope of this guide. Check out the RNA101 guide and there will hopefully be more info there! For now it can be summarised; rRNA helps the Ribosomal proteins assemble in the correct order, then bind and move the messenger RNA.
Prokaryotic:
30S - Decodes and binds the mRNA, matches it to tRNA.
50S - Catalytic function, binds AA-tRNAs and facilitates formation of the peptide bond.
Eukaryotic:
40S - Decodes and binds the mRNA, matches it to tRNA. Recognises 5’ cap.
60S - Catalytic function, binds AA-tRNAs and facilitates formation of the peptide bond.
The Ribosome has three active sites that the mRNA will be pulled through. The mRNA moves along 3 base pairs at a time, moving each codon through the three sites in the following order;
A (aminoacyl) - In the A site the ribosome seeks out a AA-tRNA molecule that matches the codon currently inside, aligning the codon and anti-codon so that the AA-tRNA will move when the mRNA moves.
P (peptidyl) - The mRNA molecule moves along 3 base pairs, pulling the attached AA-tRNA complex with it. The ribosome then removes the AA from the tRNA and catalyses a bond to add the amino acid to the growing AA-chain, lengthening it by one.
E (exit) - The mRNA molecule moves along another 3 base pairs, leaving the AA but pulling the tRNA molecule along. It is now able to exit the ribosome and can be reused by the tRNA activating enzyme to make a new AA-tRNA complex.

The steps of a Translation reaction that occur during the production of a protein within a ribosome are:
Initiation - The ribosome assembles around the target strand of mRNA. As the start codon enters the ribosome, the first AA-tRNA molecule, known as the ‘initiator tRNA’ binds directly to the P site of the ribosome, leaving a methionine molecule to start off the protein. An AA-tRNA complex matching the codon in the A site moves into place and is bound to the mRNA.
Elongation - The mRNA molecule moves one codon along through the Ribosome complex, pulling the newly associated AA-tRNA from the A site into the P-site. In the P site, a peptide bond is formed between the methionine and the new amino acid. The initiator tRNA (now missing its methionine) is moved to the E site, where it is able to leave the Ribosome. A new AA-tRNA molecule is found to match the codon in the A site. This process is then repeated. Additional ribosomes may bind the mRNA molecule as it passes through the first ribosome, starting a translation medley.
Termination - When the stop codon is reached the ribosome releases the newly made polypeptide and disassembles itself, ready to find a new protein to translate.

After Termination, the protein chain is complete and the cell has a new protein, so we’re all done? Not quite.
3) Folding - Turning a polypeptide chain into an active protein
As you learnt while attempting to mentally visualise DNA, the arrangement of nucleic acids in 3D space (tertiary structure) can be just as important as the 2D linear sequence. To further complicate things, proteins have a 4D (quaternary structure) that describes the arrangement of multiple protein subunits into a fully functional molecular machine. After translation, the host cell must now introduce the new protein to the correct environment to encourage perfect folding. It is at this stage where we see another large divergence between prokaryotes and eukaryotes;
Prokaryotes
Occurs once protein synthesis is complete.
Folding can be assisted by chaperone proteins
Reductive Folding - The cell cytoplasm is a naturally reductive atmosphere, proteins that fold naturally in this atmosphere will tend to self-assemble into the correct shape. Those that do not may be produced alongside a chaperone to ensure that folding is successful.
Oxidative Folding - Vesicles in the cytoplasm and the periplasmic space are oxidative environments. This makes these spaces ideal for folding proteins that require an oxidative space, such as those containing disulphide bonds.
Eukaryotes
Rough Endoplasmic Reticulum - Location of protein synthesis by ribosomes, protein folding is also initiated here. Chaperone proteins in the lumen of the Rough ER help the protein to fold correctly.
Golgi Apparatus - An organelle for the folding and delivery of proteins and fats. Proteins that enter the golgi body are folded into their final active form, then delivered to where they are needed, or simply released.
The Golgi Apparatus exhibits redux and pH homeostasis - allows for tailor-made environments for niche folding requirements. This is done via a series of membrane pumps that switch themselves on when changes in pH or ion concentration are detected.
As each domain of a protein is synthesised, it can be subjected to folding in the Rough ER while downstream protein continues to be translated.
Both the Rough ER and Golgi Body can play a regulatory role, inhibiting or accelerating the production of the proteins according to instructions conveyed by biochemical feedback loops.
e.g. When molecule A is present in excess, cancel translation and folding of molecule B.
More details on the Proteins101 page!
Reproduction
Now you can see how the proteins necessary for the reproduction of DNA are made, we can examine what happens to DNA during these processes.
During meiosis, the production of gamete (sex) cells, intentional DNA recombination events occur in a controlled manner to ensure sufficient variation in potential offspring. This is an evolutionary trade-off that allows eukaryotic organisms to be adaptive to change despite significantly longer generation cycles. The role of meiosis is to produce sex cells that will produce viable but varied offspring.
During mitosis, the reproduction of somatic (body) cells, every attempt is made to preserve the exact sequence of DNA as it is copied from parent cell to daughter cells. Failure to do so can result in immediate cell death, degenerate protein production, or the inhibition of proteins which may eventually lead to cancerous cell growth.
The same is true for the replication of single-celled organisms during binary fission - mutation events can be catastrophic. For both of these processes, there are DNA error-checking and repair mechanisms in play that help minimise the number of mistakes that are carried through to the next generation. The role of mitosis and binary fission is to perfectly replicate the genome without any mistakes. However there are significant differences in how this objective is completed, owing to the long evolutionary timeline distinguishing prokaryotes from eukaryotes.
1) Eukaryotic Reproduction: Meiosis & Mitosis
Meiosis is a process specific to sexual reproduction, producing daughter cells with only half the required DNA for a complete organism (gametes). Most meiosis-performing organisms will have dedicated reproductive organs that produce and store gametes, waiting for the right moment. In humans, these organs are the ovaries and the testes. In human females, all meiosis occurs during fetal development. In human males, meiosis is a continual process that produces fresh gametes from sexual maturity until old age. *please stop sniggering in the back row* After successful conception, the gametes (n chromosomes) fuse to form a zygote (2n chromosomes). This single cell has the potential to become any cell in the body, making it omnipotent.
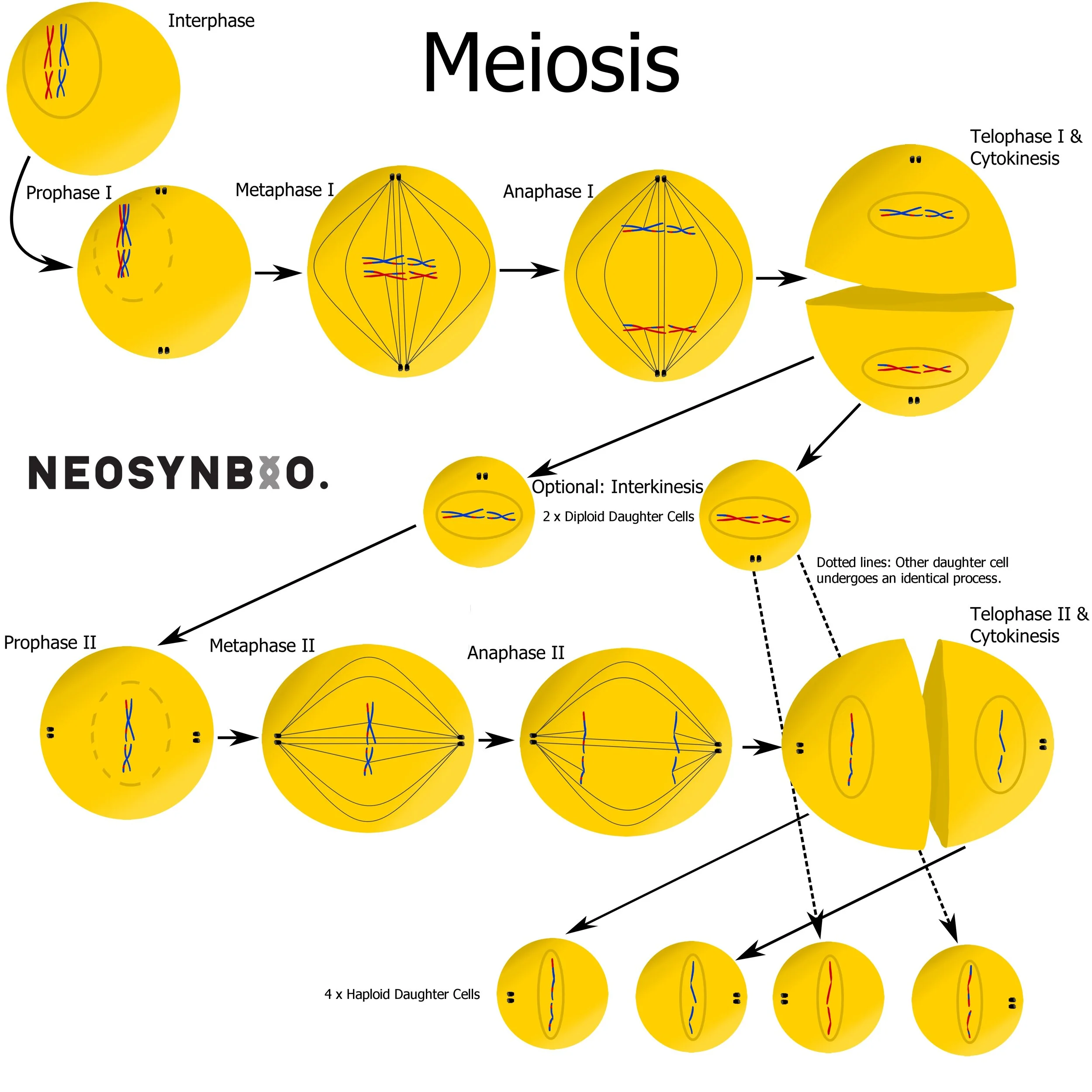
Stages of Meiosis:
Interphase - Chromosomes are replicated but remain joined as two sister chromatids.
Prophase I - Chromosomes condense, homologous chromosomes cross over forming a bivalent chromosome. Matching regions of DNA undergo homologous recombination, swapping DNA between matching regions. The nuclear membrane dissolves, exposing the interior of the cell to the environment.
Metaphase I - Spindle fibres originating from centrosomes connect to each bivalent chromosome at the centromeres. The spindles help align the bivalent chromosomes along the equator of the cell.
Anaphase I - Contraction of the spindle fibres pull apart the bivalent chromosomes apart. One set of homologous chromosomes is pulled to either centrosome, resulting in a full genome (2n) at either pole of the cell.
Telophase I and Cytokinesis - The chromosomes decondense and the nuclear membrane reforms. The membrane now separates the two diploid (2n) daughter cells.
Optional: Interkinesis - Depending on the environment and the type of sex cells there may be a growth phase. Unlike interkinesis, the DNA does not replicate itself to form sister chromatids.
Prophase II - The centrosomes rotate 90° to the perpendicular poles of the cell. The chromosomes condense and the nuclear membrane dissolves once more.
Metaphase II - Spindles from the centrosomes attach to the centromere of each chromosome, aligning them along the equator.
Anaphase II - Contraction of the spindle fibre pulls apart the centromere, separating each chromosome into two sister chromatids.
Telophase II and Cytokinesis - The cell membrane reforms around the cells, resulting in 4 daughter cells. The (n) chromosomes decondense to their native state, resulting in four haploid gametes with varied sets of (n) chromosomes.
A cytoplasmic bridge may still exist between daughter cells that cannot last long on their own e.g. sperm.
Possible sources of variation:
Parentage - The original set of homologous chromosomes came from different parents and will therefore exhibit the greatest difference.
Homologous Recombination - The crossing over event in Prophase I can result in entirely new and unique combinations of genes within a chromosome, combining genes from both parent chromosomes.
Independent Assortment - The arrangement of the bivalent & monovalent chromosomes during Metaphase I & II respectively will affect the end-state combination of chromosomes in the daughter gamete.
Imagine telling 46 people to line up as couples in the middle of the room, spin around and then each pick an opposite wall to go to. Repeat this a million times. This creates a staggering number of variables without recombining the chromosomes.
Similarly the attachment of the spindles from either pole of the cell results in a random combination being pulled to each pole during Anaphase I & II.
This can be counted as an extension of the mechanism of Independent Assortment.
Errors during Anaphase I & II can result in an excess/lack of chromosomes in the final daughter cells, resulting in a genetic disease e.g. Klinefelter’s syndrome, Trisomy 21, XYY Syndrome, etc.
Mutations - Errors can occur in the germ-line cells where meiosis occurs, or replication errors can occur during the Interphase. Each will result in a variation in the gametes
Sexual Reproduction - The choice in partner (or DNA donor) will have another significant effect, contributing a full half of the final genetic material to the zygote.
After conception, mitosis takes over. Mitosis starts during fetal development and once the organism is fully grown it is responsible for the process of cell division. Cells produced by mitosis have a complete set of chromosomal DNA (except red blood cells which lack a nucleus). All eukaryotic organisms will rely upon mitosis to constantly replace cells as they succumb to age and entropy. As the zygote begins to divide, certain daughter cells will begin to specialise (pluripotent > multipotent > unipotent). The now unnecessary sequences of DNA (e.g. brain-specific proteins in liver cells) are disabled by folding them extremely tightly around the histones. These instructions are provided by adding chemical signals to the histone tails. Despite not being expressed, the unused sequences of DNA continue to be copied through successive generations. Certain chemical signals can reactivate disabled genes. If these genes are responsible for growth or division and remain enabled, the result may be a cancerous tumour. In-vitro manipulation of these pathways can allow a researcher to induce specialised cells to become stem cells once again, negating any need for fetal stem cells in research.
While any DNA-containing cell has the potential for mitotic division - mitosis must occur in a controlled manner. Uncontrolled mitosis will lead to cancer. As a result, many eukaryotic species have dedicated multipotent or unipotent stem cell lines for common mitotic division, such as the production of new white/red blood cells, replacement of liver cells or the growth of new neuronal cells. Eukaryotic cells follow a regulated Cell Cycle that dictates when they are allowed to divide;

Starting from the last division, the cell begins the G1 Phase. The cell will grow in size and begin to duplicate all of its organelles, except for the nucleus. Depending on external and internal signals, the cell may enter a resting “quiescent” state known as G0 for an indefinite period of time. G0 is similar to an extended G1 phase. At the end of G1, error-checking DNA polymerases review the sequence of DNA for damage. If there is an unrepairable level of DNA damage, replication is halted and the cell may be scheduled for apoptosis (cell suicide).
The Cell enters S Phase, during which all of the DNA in the nucleus is replicated. Homologous chromosomes remain bound at the centromere. During this process (The Intra-S Checkpoint) the DNA is again checked by enzymes for damage. At the end of replication, the polymerases perform a final check to certify that replication was successful. The detection of unrepairable errors during this period results in the termination of replication and possibly apoptosis.
The cell enters the G2 Phase, an optional and shorter growth period that is similar to G1. Some cells and cancers skip this phase entirely, resulting in quicker cell reproduction. Error-checking polymerases perform a final analysis of the copied DNA sequences and if everything is correct the cell prepares to divide.
Mitosis then begins (diagram below). There is a final checkpoint during Metaphase to ensure correct spindle attachment. Mitosis will not proceed until every chromosome is correctly attached. This checkpoint is critical for ensuring that the daughter cells each receive the correct number of chromosomes.

Stages of Mitosis:
Interphase (G1/G0-S-G2) - Long intermediate phase between replication, especially if the cell enters the G0 resting state. During the S phase, DNA is replicated to form sister chromatids.
Prophase - DNA condenses as cohesin protein is replaced by condensin everywhere except the centromere.
Prometaphase - The nuclear envelope fragments into smaller vesicles, allowing the centrioles to assemble microtubules that reach inside the nucleus and attach to the DNA. These microtubules are pulled taut, until there is an equal force pulling the sister chromatids in either direction - with only the cohesin centromere holding them together.
Metaphase - Chromosomes align along the cell equator and the structural integrity of all the spindles is examined by error-checking enzymes. Errors in alignment or spindle strength will result in the termination of mitosis.
Anaphase - The cohesin holding the sister chromatids together is dissolved by separase and the microtubules in the spindles that are attached to the chromosomes (kinetochore microtubule) are shortened. This pulls the chromosomes to the centrioles at either pole of the cell. The polar microtubules remain attached.
Telophase & Cytokinesis - When the chromosomes reach the poles, the nuclear membrane reforms and the DNA decondenses, condensin replaced by cohesin once more. The cellular membrane pinches off at the cleavage furrow, separating the cytoplasm of the two genetically identical daughter cells.
Possible Sources of Variation:
Mutation events - Unrepaired errors produced during interphase will be carried on to the daughter cell. Double stranded DNA breaks during this process may result in random indels (insertions and deletions).
Sub-diploid or polyploid events - Errors in microtubule attachment and tugging will result in the daughter cells receiving an unequal quantity of chromosomes. The error checking steps in the metaphase help to prevent this from occurring too often.
After successful division via Mitosis, the two daughter cells begin their life in G1 phase.
2) Prokaryotic Reproduction: Binary Fission
Single-celled organisms lack the luxury of dedicated sex organs that can store specially made gametes - they have to give their life to produce offspring. Or perhaps this is a form of immortality? They probably don’t notice or care.
Binary fission is reproduction by splitting in two. The cell makes a copy of the circular DNA genome by starting at the Origin of Replication and working 5’ > 3’ along both strands. One strand is produced continuously (leading strand) while the other is produced in small discontinuous stretches known as Okazaki Fragments. These discontinuous fragments are later linked together by DNA ligase which repairs the backbone in order to produce a second contiguous strand.

Once the chromosome and plasmids are completely duplicated, each copy drifts to opposite sides of the cell. Each cell accumulates sufficient resources (proteins, fats, organelles, etc.) to live independently. Then the membrane pinches off - producing two daughter cells. This is an excellent way to remain genetically stable over multiple generations. The drawback of this system is a reduced ability to cope with environmental change. There is no sexual partner to introduce new genes, so the bacteria must rely on genomic mutations or a phage infection in order to introduce potential variability. These changes are untested, there is no viable sexual partner to prove that these mutations won’t kill the host. In fact, most do. Fortunately, bacteria have plasmids;
Plasmids are small circles of DNA that contain expressible genetic elements. They provide the much needed rapid and trustworthy adaptability that binary fission fails to provide. Plasmids that give an evolutionary benefit are copied during binary fission and can even be shared between bacteria that are local to one another. Plasmids that are inefficient and provide no benefit are ‘spat out’ by the cell and will not be passed down to daughter cells. Some plasmids can even integrate themselves into the genome permanently, at a selected or random location. These plasmids don’t survive multiple generations unless they manage to integrate into the genome.

Four stages of Binary Fission;
Replication - The chromosome is unwound and the origin of replication is opened to allow access for DNA polymerase. Two new strands are synthesised, running in each direction. These identical chromosomes separate.
Plasmids contain their own origin of replication. They are replicated independently of the chromosome and the number of copies is based on the copy number of the plasmid.
Growth - The host grows larger, increasing the volume of the cytoplasm. The chromosomes drift towards the opposite poles of the cell. A large quantity of the protein FtsZ migrates to the centre of the cell.
Segregation - The FtsZ proteins form a ring in the centre of the cell. This causes a septum to form, allowing cell wall and cell membrane proteins/lipids to accumulate.
Fission - The FtsZ ring completely pinches the cell in two, resulting in two genetically identical daughter cells.
How does DNA regulate itself?
So far we’ve examined the properties and functions of DNA in depth. You should now have a relatively strong understanding of how the contortion and folding of a DNA strand can influence whether or not it is converted into a protein. This means you can finally start to try to understand the mechanisms of action behind the expression of DNA. Before we dive into the world of transcription-level regulation, it’s important to acknowledge the existing limitations: Our current technology isn’t able to reliably interpret the methylation of histone tails and our ability to selectively influence the 3 & 4 dimensional structures of DNA is hampered by this. This seriously caps our ability to understand the full picture, although it won’t be long before we unlock the next piece of the puzzle. Likewise there are additional regulatory steps that occur after the mRNA is created, known as translational-level regulation. We’ll explore those systems more in the RNA101 guide. There you will also find more information about other DNA/RNA interactions that might influence protein expression, such as ‘silencing RNAs’ (siRNAs).
To understand the regulation of DNA at the transcription-level, let’s roll all the way down to our 3° of Abstraction, the linear sequence. We may occasionally need to jump up to the 2° model to imagine the sequence folding around a single molecule, but otherwise we’re just going to think of our DNA as a linear/circular sequence of base-pairs. We may bring in additional molecules into our model at times, such as RNA or chelating proteins, but lets ignore the rest of the cell.
Surrounding any gene will be the expression machinery, DNA sequences that perform specific roles to assist the successful creation of a protein when it is needed. Most of the time the expression machinery will be adjacent or at least local to our gene, but the world of DNA is incredibly complex. Research shows that genes in more complex genomes can be affected by distant sequences, or by sequences on entirely separate chromosomes. This implies the existence of more complex regulatory pathways, the mechanisms of which we do not yet fully understand.
Within the world of expression machinery that we actually can comprehend, regulatory functions can be broken into two broad categories;
Promotion - Make more protein!
Repression - Make less protein!
Transcription level regulation is not a world of binary choices, expression systems are often described in terms of their strength rather than in absolute ON/OFF terms. A strong promoter will encourage the production of more protein than a weak promoter, likewise a weak repressor will allow more protein to be produced than a strong repressor. Most expression systems can be switched on and off, allowing them to technically perform both functions ie. switching off a promoter will have a repressive effect.
Transcription factors are proteins that bind to a specific region of DNA in order to influence the transcription levels of downstream (in the 3’ direction) sequences. The function of many promoters and repressors is to bind to a transcription factor, which in turn will control the level of downstream expression. Of course the transcription factor itself must be transcribed and translated before this can occur. This means that the transcription factor may have its own regulatory genes, with their own associated transcription factors. And so on…
My favourite analogy that I was taught at university was the ‘playground of see-saws’. One gene produces a protein that changes another gene which produces a protein which changes another gene, and so on. Unfortunately not all metabolic pathways are quite so linear, soon we have molecules jumping onto multiple see-saws and there is chaos in the playground…

Hopefully this colourful metaphor will help you understand that a single change in the concentration of one molecule can set off a cascade of reactions, changing the set of active transcription factors which will in turn catalyse the synthesis of a completely different set of genes.
E.G. The Lac Operon in bacteria
When bacteria are starved of glucose, the molecules involved in glucose metabolism undergo a change that activates the lac operon. This is a set of genes under a single promoter responsible for producing the enzymes required to break down lactose for energy. The three proteins required for this process are;
lacZ - lactase (aka. β-Galactosidase) which breaks down lactose into glucose and galactose. This gene circuit exhibits polarity, whereby the upstream genes are translated the most, so lacZ is produced in a higher volume than the following two.
lacY - β-Galactosidase permease, a transmembrane protein that transports lactose into the cytoplasm. The amount of transmembrane proteins of each type at any one time is influenced by external regulatory pathways as well. The glucose metabolic pathway also has the authority to shut down this protein to cease lactose transport in the event of glucose reappearing.
lacA - Scientists still fight about the exact role of lacA, cells can survive without it, but there is some slight (+5% survival rate) evolutionary advantage. It is expressed far less than the other two. It may have a role of detoxification, as a transcription factor or as a chaperone protein.
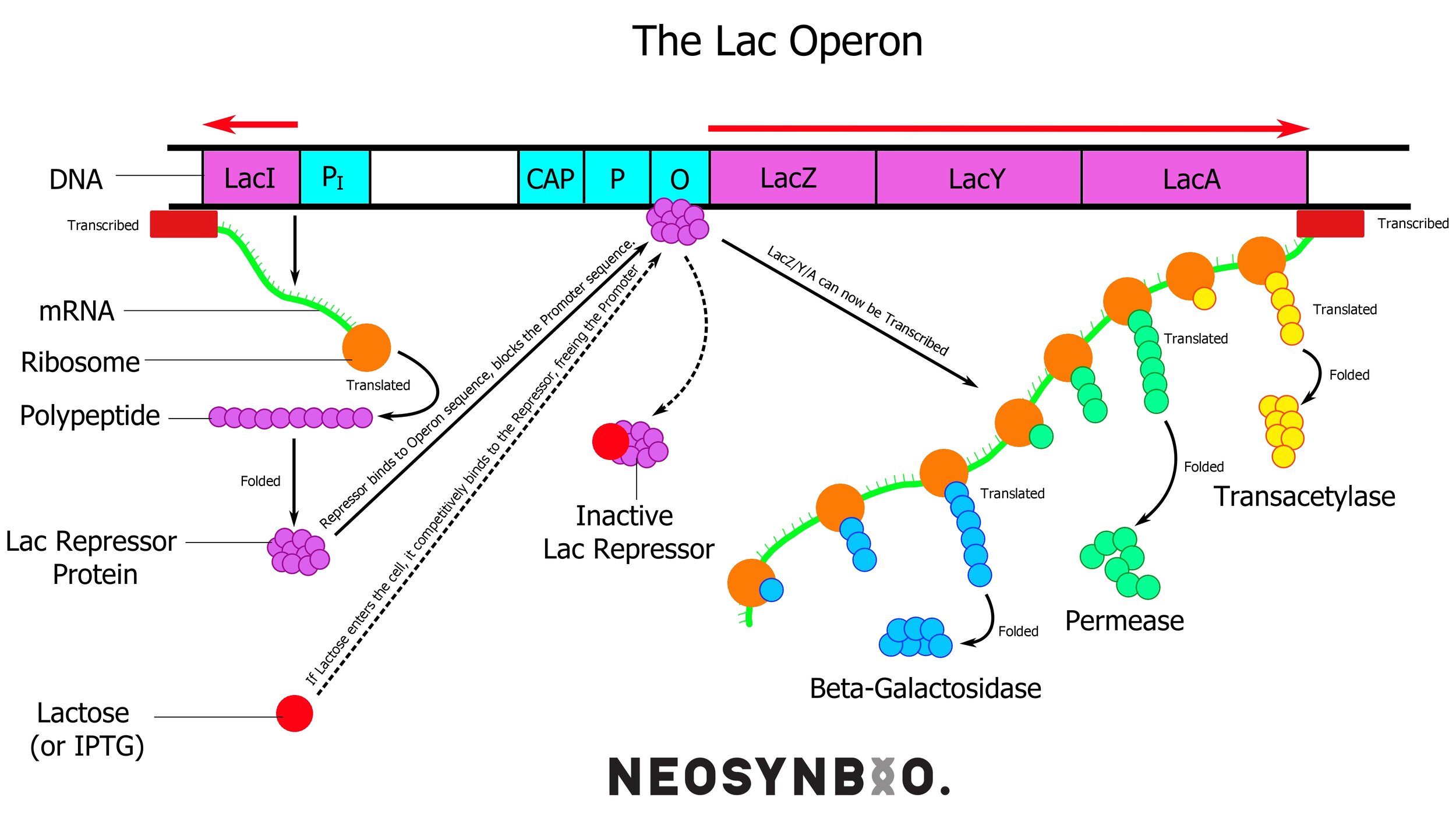
External to the lac operon we find a fourth gene that is under constitutive (always on) expression; lacI - the lac repressor. This protein is always active, unless it is bound to allolactose. This molecule is similar to lactose and arises in the cell as lactose builds up beyond what the existing β-Galactosidase can handle. When no allolactose is present, the active protein binds to the operator of the lac operon - preventing the RNA polymerase from proceeding.

The CAP molecule is a protein synthesised separately, similarly to lacI. It binds very tightly to cyclic AMP - a molecule that is used very heavily during glucose metabolism. An excess of cAMP implies that there is not enough glucose to go around and the CAP molecule gets a chance to bind. When this occurs, it may attach to the CAP site of the DNA strand to significantly boost how quickly it attracts & binds RNA polymerase. This effectively gives the lac operon a two-stage solution for lactose metabolism, devoting the minimum number of resources necessary to metabolise what is needed.
Only need to chew on a bit of lactose? Remove the repressor and produce a bit of lacZ
Oh god we’re running out of energy and the glucose is gone! Pull out all stops, bind the CAP-cAMP to the CAP site, remove all repressors, produce lacZ everywhere, chuck some lacY into the membrane. Create some lacA for??? WOO!
Oh wait we found glucose again. Shut it down. Block off that lacY and stop producing lacZ.
I never cease marveling at the economics of evolved metabolisms.
The lac operon is everyone’s first taste of how genetic machinery interacts, you’ll likely come across many more as you attempt to put some of these protocols into action. But there's a reason why I’ve started with the lac operon and that is because it is also easy to take over for your own ends. Lactose (or IPTG which looks a lot like lactose to a bacteria) will become your “ON-Switch" for bacterial expression, allowing you to command the production of the protein with a single drop from a pipette.
Or perhaps you’re more interested in the constitutive expression exhibited by the LacI gene. Having a gene ‘always on’ has draw-backs (the cell may grow slower) but it’s a lot easier if you just want to make stuff glow. The lac operon (+ friends) have a ton of handy tools contained within, so lets examine how you might take advantage of this as a researcher…
How can you (the researcher) make use of these features of DNA?
When working in simple single-celled systems, a skilled researcher can instruct a cell to produce a protein on command. The DNA sequence surrounding the inserted protein of interest is just as critical to the success of a project as the protein sequence itself. Without a complete complement of genetic parts a synthetically designed system will fail to function.
Early on, I’d recommend learning genetic design with plasmids as they’re easier to work with than genomic DNA. You can learn more about plasmids in the PLASMIDS101 guide. Also known as a backbone, the plasmid is like a CD-ROM (or USB Flash drive) that you can freely insert and remove from bacteria to recode them. Genomic DNA changes are more like a change to the computer’s firmware in this extended metaphor. You can learn how to select an appropriate backbone on this page;
Backbone Selection
Ordering a backbone is easy. Just head on over to AddGene, set up an account and browse all the amazing plasmids shared on that platform! They will send you the plasmid inside a host strain of bacteria as an ‘agar stab’. As a living organism this may require consultation with a regulatory authority. In Australia this is the OGTR and Border Force. Alternatively you can ask a friendly synthetic biologist if they have any backbones they want to share. Most of us get weirdly excited about our plasmids and just can’t wait to share them. As dried material on blotter paper, plasmids are not considered GMO or restricted in any jurisdictions. This may change in the future as people realise what a massive biosecurity hole this is.
Often the backbone will contain genetic parts relevant to your final design, so it’s important to note what parts are internal or external to your cloning sites. If the promoter is outside of the cloning site, it’s important not to double up with a promoter in your designed gene. Likewise don’t assume that you won’t need a promoter because the plasmid has one - if you ligate in the wrong place and end up with no promoter, it is game over, back to square zero. Once you’ve got a plasmid and you’re sure of which parts you do and don’t need, it’s time to design your gene;
Gblock Design
Once your gene is designed you will need to get it synthesised. This becomes cheaper by the year and there is a competitive market, so google around for a good deal. Errors during the manufacturing of your gene will be disastrous for your project, so make your decision based upon quality as much as price. I personally use IDT for my gene synthesis, but that’s because I’ve limited options in Australia. I’ve never had any problems with genes ordered from them and I believe they’re a good industrial standard to price check against.
Once your gene arrives, it is time to cut it into your plasmid. There are a number of methods for doing this. You can pick any of these, but keep in mind that your choice will impact your Gblock design;
After the construction of your plasmid, you will need to insert it into a specially prepared host strain;
Plasmid Insertion
An alternative to plasmid usage is to insert your gene into the genome itself. Genomic integration offers a number of unique advantages and disadvantages over plasmid insertion. Rather than existing as a solitary circle of code, your gene will be inserted into the larger genome of the host microorganism, where it will remain generation after generation. While plasmids are copied during binary fission, they will be ‘spat out’ by the cell if they no longer provide any evolutionary advantage. This means the researcher must constantly supply the bacteria with fresh antibiotic to force the bacteria to keep the plasmid.
An edit to the genome is much more permanent and doesn’t require antibiotics to maintain. Changing the code of the organism itself (rather than providing auxiliary code) is considered ethically problematic by some groups. Depending on your vector choice you may face some challenges; an integrative plasmid may insert randomly (never good) or over a specific gene (more manageable, but not good if the gene is important). Genomes are also highly conserved between generations for a reason - large changes may lead to increasing levels of inefficiency in the host. Our inability to comprehend the more complex picture without the 2-3 degrees of abstraction leads us into pitfalls we could never have seen coming. Adding 300 bp into a region thought to be junk DNA may lead to inexplicable death of the host - an interesting result to be sure, but not ideal.
If you do plan on working with integrative plasmids, I implore you to stick to microorganisms until we’ve a deeper understanding of more complex genomes. If you really want to contribute to this body of knowledge, perhaps consider a knockout study. That way, when you knockout a critically important gene for your host - you can at least record the resulting changes in the transcriptome and proteome to contribute to science!
GLOSSARY OF NEW TERMS
3’ Polyadenylation - The addition of a polyA tail to a messenger RNA molecule after the process of transcription in Eukaryotes. It is a stretch of RNA Arginine bases that covers the end of the mRNA molecule, allowing for stable and reliable transport out of the nucleus, to the Rough Endoplasmic Reticulum.
5’ > 3’ – Directionality of DNA. Systems that run in this direction along a DNA strand have a forward motion, systems that run 3’ > 5’ have a reverse motion. When DNA is written as a raw sequence, always assume it is the 5’>3’ of the positive (coding) strand.
5’ Cap - The addition of a specially modified nucleotide (7-methylguanylate) to the 5’ end of an messenger RNA strand during the process of transcription. This results in a more stable mRNA molecule and more reliable translation of proteins.
Agarose Gel – Protocol for measuring the length of DNA by size-based electrophoresis. Works due to DNA carrying a linear negative charge.
Amino acid - The basic building block of polypeptides/proteins. This molecule contains a central carbon, flanked by a hydrogen, a Carboxyl (-COOH), an amino (-NH2) group and a variable side chain that gives it its unique characteristics. There are only 20 naturally occurring amino acids.
Aminoacyl-tRNA synthetase - Enzyme responsible for bonding Amino Acids to anticodon-bearing tRNAs for the ribosome to use during Translation. A unique aminoacyl-tRNA synthetase is produced for each tRNA, which allows for extremely high specificity. Different species will preferentially produce more or less of these enzymes, resulting in a codon preference. This can be overcome in genetic design via codon optimisation.
Anneal - Hydrogen bonds forming between the matching bases of two DNA strands (A-T, C-G) to form a double stranded sequence.
Anti-Codon - Three base-pair sequence that is the opposite (A becomes T (or U for RNA), C becomes G) of a codon. Anti-codons can be found on the non-coding strand of the original sequence and on the tRNA’s used for translation. The ‘frame’ of the anti-codons is set by the start codon on the coding strand.
Apoptosis - Carefully ordered self-destruction of a cell due to its failure to pass an important quality assurance checkpoint. Cells with DNA damage or replication errors are ordered to commit suicide, packaging active enzymes into vesicles to prevent them from causing collateral damage to neighbouring cells.
Aptamer - DNA or Protein molecules that selectively bind a target, but do not catalyse a reaction - a similar function to an antibody. Unlike antibodies; aptamers are smaller, are synthetically produced and bind their target with higher affinity.
ATP molecule - Adenosine 5’-triphosphate is a ubiquitous molecule in metabolic processes, responsible for moving readily available energy around the cell. Adenosine 5’ diphosphate (ADP) is combined with a phosphate during cellular respiration to produce an energy-rich bind. This bond can be easily broken by enzymes that require energy to perform their function. In Animals, Plants and Fungi, ATP is produced within the mitochondria, the powerhouse of the cell. Bacteria lack mitochondria and instead produce ATP via the Krebs cycle in aerobic conditions, or fermentation when oxygen is unavailable.
Backbone - Nickname for a functional plasmid that can host an inserted gene.
Bacteriophage - Virus that infects only bacteria. Bacteria and Viruses have been locked in an arms race that goes back aeons. A bad bacteriophage infection in a biotech space can be devastating for everyone in the lab. Keep DNA backups!
Base-pairs - Pairs of nucleic acids that are a feature of DNA and can occur during the self-association of RNA. Hydrogen bonds form between the nucleic acids, holding them together strongly (but not as strongly as the bonds holding the nucleic acid to the backbone). A always pairs with T with two Hydrogen Bonds, C always pairs with G with three Hydrogen Bonds. The extra bond makes the C-G base pair slightly stronger than the A-T base pair.
Buffered Solution - Combination of weak acid/strong base or strong acid/weak base that keeps a persistent pH even as additional ions are added. Extremely useful while handling biological substances that do not tolerate pH changes well.
Binary Fission - Bacterial asexual reproduction by replication of the genome and separating into two distinct ‘daughter cells’.
Cell Cycle - Process of cell division dictated by internal and external chemical signalling pathways. A correctly functioning cell cycle helps ensure that only cells with accurate DNA replication are able to divide.
Central Dogma of Molecular Biology - DNA > mRNA > Proteins
Centromere - DNA sequence that binds homologous chromosomes together prior to replication that is bound by the spindle during the Metaphase of Mitosis/Meiosis.
Chaperone Proteins - Proteins that assist in the correct folding of new proteins that may not fold correctly without assistance.
Chelating agents - Metal ions that bond to an organic molecule (DNA or protein) to produce a conformational change.
Chromosome - Packaged DNA that is part of the genome of an organism. Humans have 23 chromosomes. Human Chromosome 1 is our longest at 249 million nucleic acid base pairs. Bacteria have simpler chromosome, made up of a single circle containing 4.6 million base pairs (Mbp).
Coding Strand - Strand of DNA that codes for the protein. The sequence of the coding strand is copied by RNA polymerase reading the non-coding strand and adding matching nucleotides (A wherever there is a T, C wherever there is a G, and vice versa). This works because the non-coding strand is the exact opposite of the coding strand). The sequence of the coding strand will be made up of three base pair codons, with the frame set by the start codon AUG.
Codon - Sets of three nucleotides on the coding strand that each code for a specific amino acid according to a code universal to all forms of life. Translation of codons to amino acids can be easily performed by finding a codon table online. Despite this code being universal across all forms of life, different species preferentially use different codons more. This means that codon optimisation is necessary to prevent bottlenecks during the biosynthesis of proteins.
Codon Optimisation - Adjusting the codons in a DNA sequence while maintaining the resultant protein sequence. Codon optimisation uses species specific modelling to determine the best codons to use for your sequence in order to prevent bottlenecks by the Aminoacyl-tRNA synthetases.
Codon Usage Bias - The preferential use of codons in the genome of a particular species which indicates the levels of Aminoacyl-tRNA synthetases available to handle the workload of producing tRNAs for translating a specific codon.
Constitutive - Always on expression. A constitutive gene is never switched off, either because the mechanism is never flipped, is broken or does not exist.
Covalent Bond - A strong molecular bond resulting from the sharing of electron pairs between atoms. Covalent bonds vary in strength, but are always significantly stronger than hydrogen bonds. This is why the two DNA strands will denature (detach) from one another when heated, but the backbone remains intact.
Cytoplasm - Internal cellular liquid composed of dissolved salts and proteins in water. Extremely complex when scrutinized at the atomic level, but often simplified for models of intracellular interactions.
Cytokinesis - The separation of the cytoplasm of two daughter cells following mitosis/meiosis in Eukaryotes or Binary Fission in Prokaryotes. A new cellular membrane completes itself around the new daughter cells.
Degrees of Abstraction - Simplified versions of reality to help our monkey brains comprehend a complex reality.
Dehydration Polymerisation - Reaction that occurs during the synthesis of the DNA backbone. A triphosphate nucleotide is brought near the growing DNA strand by DNA polymerase and two phosphates are removed to provide the energy for the reaction. The polymerase facilitates the formation of covalent bonds between the phosphate and ribose sugar to add the nucleotide to the growing chain. A water molecule is released during the reaction, with an OH from ribose sugar and an H from the phosphate group.
Diploid - The number (2n) of chromosomes in a somatic (body) cell of an organism that reproduces via sexual reproduction. There is a copy of every gene in a diploid genome, although most of the time only one of the pair (the dominant gene) is actually expressed.
Disulphide Bonds - A bond between two cysteine amino acids within a polypeptide chain. Two sulphur molecules are bonded between the cysteines, resulting in a change in the folding of the protein.
DNA - Deoxyribonucleic acid, a chain of nucleic acids bonded within a sugar-phosphate backbone that codes for biological life.
DNA Ligase - An enzyme responsible for repairing breaks in the DNA backbone, repairing bonds between ribose sugars and phosphate molecules via a reaction known as dehydration polymerisation. T4 DNA ligase (hijacked from the T4 phage) is an examples of a ligase enzyme which can be used by a researcher to ligate DNA in the lab.
DNAzymes - Small stretches of DNA capable of catalysing or performing a biological reaction.
Downstream - In the 3’ direction of.
Dye Intercalation - The insertion of fluorescent dye molecules in between the bases of DNA within the double helix. The helix unwinds slightly, exposing an internal hydrophobic environment that the dye molecule can slip into.
Epigenetics - Changes to genetic expression caused by factors other than changes to the sequence of nucleic acids. Caused by a multitude of factors, such as the methylation of cytosines or histone tails. An emerging and poorly understood field.
Eukaryotes - Organisms with membrane-bound organelles and a distinct nucleus enclosing the nucleic acids. Range from single-celled yeast, to complex organisms such as humans.
Expression - Genes that are transcribed and translated into proteins are being ‘expressed’. Expression may refer to one protein, or a pattern of proteins that result in a particular allele or phenotype. Genetic sequencing and protein assays allow us to be highly specific about mutations and the resulting changes - however you may also encounter these less specific terms;
Allele - Alternative forms of expression, resulting from different gene sequences coding for a similar protein. A more specific way to describe an allele is with the mutations that created it.
Genotype - The genetic makeup of an organism, including the combinations of genes that make up the genome. Generally described in terms of dominant/recessive genes, or ‘types’. e.g. ABO blood types.
Phenotype - The observable features of an organism, resulting from the interaction of the genome with the environment. Mostly qualitative term that has led to plenty of misconceptions.
Expression Machinery - Proteins/Enzymes required to produce a protein, from transcription to translation to folding. The capacity of a cell to produce new proteins is limited by the capacity of these systems. Useful as a catch-all term when you’re unsure which specific enzyme is causing a problem.
Exon - Regions of the mRNA molecule in Eukaryotes that will be translated into protein. After transcription, Eukaryotic mRNA undergoes splicing, whereby non-coding introns are removed, leaving coding exons. This allows for adaptable recombination of protein sequences to perform specific functions as required. Certain regions of the protein are conserved, while the active region is swapped out for something more appropriate. Recombination of exons by splicing is an example of post-transcriptional regulation.
Folding - The contortions and overlapping within three-dimensional space of DNA or protein molecules. At this scale, folding becomes critical to the functional properties of organic molecules - similar how to metal might be folded into a useful shape.
Forward Mechanism - Runs in the 5’ > 3’ direction along DNA.
Gamete - A germ-line sex cell with half of the genetic information necessary to form a complete organism. Two gametes merge during sexual reproduction to form a zygote, the first omnipotent cell that will go on to form a complete organism.
Gblock™ - Nickname for an artificially synthesised strand of double stranded DNA (125-3000 bp) by IDT. Gblocks are also referred to as oligonucleotides, a term that also describes smaller fragments of DNA <125.
Gene Cascade - A series of genes switched on and off in a specific order, most often used during initial development of an organism. Gene cascades involve the intricately complex interactions of promoters and repressors in order to ensure an organism develops in the correct order.
Genetic Parts - Individual sections of DNA code that are responsible for the various functions required by the researcher for an experiment. During the expression of a protein, this might be: Promotor, Operator, Ribosome Binding Site, Gene of Interest with start and stop codon, Terminator, all flanked by a Multicloning Site Prefix and Suffix. Working from a database of standardised genetic parts (such as the iGEM parts database) is an extremely useful way to skip a lot of painful trial and error in genetic design.
Genome - The entire set of chromosomes, containing all of the DNA necessary to successfully recreate the organism for the next generation. The human genome is 6.4 billion base pairs in size, spread across 46 chromosomes. This is made up of 3.2 billion base pairs inherited from the original sperm and egg. For comparison, the entire E. coli genome fits within a single 4.6 million base pair chromosome that can replicate its entire length in less than 30 minutes.
Genomic DNA - Series of nucleic acids that codes for the entirety of an organism. Varies in structure from simple 1,000,000 base pair circular genomes in prokaryotes, to 6,200,000,000 base pairs across 42 chromosomes in diploid human cells.
Genomic Integration - The insertion of a gene into the genome of an organism. This is process that occurs naturally, such as with integrative retroviruses. Genomic integration can also be artificially reproduced in the lab, resulting in a permanently changed organism. Changes will be carried over to the offspring if changes are made to a gamete, zygote, germ-line cells or single-celled organism.
Golgi Apparatus - Eukaryotic organelle responsible for some protein folding (after synthesis in the Rough ER) as well as the transport and folding of protein and lipids. Small vesicles are budded off the membrane of the Golgi body, secreting the protein/lipid while maintaining the same mildly acidic and oxidative environment to ensure it holds its structure until it reaches its destination.
Haploid - The number (n) of chromosomes in a gamete (sex) cell of an organism that reproduces via sexual reproduction. There is only one copy of each gene, a second copy is required in order to initiate cell replication and the creation of a complete organism.
Histones - Basic (alkaline) proteins responsible for the wrapping and packaging of DNA in a chromosome. Histones form octamers that each contain two copies of the four histone proteins (H2A, H2B, H3 and H4).
Homeostasis - The maintenance of a consistent internal environment, e.g. pH, RedOx, Temperature, Osmotic pressure, etc.
Homologous - Share a matching structure, but not necessarily a matching sequence. You receive one homologous chromosome from each parent. Each will code for the same proteins albeit with slight variations, or errors that result in no protein at all.
Homologous Recombination - Occurs during the ‘crossing-over’ event in meiosis, matching chromosomes line up and exchange matching regions to create entirely new genetic combinations on the resultant chromosomes. When a double stranded break occurs in a mature organism, the homologous chromosome is used as a repair template (HDR) - potentially resulting in unintended homologous recombination.
Homology Directed Repair (HDR) - Repair of a double-stranded break in an organism using the homologous chromosome as a template for the process. Significant upstream and downstream homology is required for the template to be used, without a nearby homologous region the break will be repaired by Non-Homologous End-Joining (NHEJ), a very error prone process.
Host - The organism that contains the DNA, RNA or protein in question. In microbiology, molecular biology and synthetic biology this will most likely be a single celled organism (e.g. E. coli or Yeast) or an extremely simple multicellular organism. When referring to diseases, the host is the organism that has been infected by a pathogen (bacteria, virus, phage, prion, etc).
Hydrogen Bond - A weak intermolecular bond formed by the electrostatic attraction between an electropositive proton (hydrogen) in one molecule and a relatively electronegative atom in another molecule.
Independent Assortment - Source of variation during meiosis caused by the alignment of the chromosomes along the equator of the cell. Since they line up in pairs and can pick either side, each pair has only two possible alignments. However there are 23 chromosomes in humans, resulting in a large number of combinations (2^23). For other sexually reproducing organisms with n chromosomes, independent assortment introduces 2^n variation.
Intracellular Machinery - The internal organelles and proteins responsible for the day to day operations of a cell. This is a catch-all term used to refer to the productive capacities of a cell in general, often when specifics are yet to be inferred.
Intron - Transcribed region of DNA that will be excised from the messenger RNA molecule, leaving only the exons to be translated. Introns provide a vital regulatory role and should not be discounted as ‘junk’.
In Vivo - Occurring on or within a living organism.
In Vitro - Occuring in the lab, exterior to the living organism.
Nucleic Acids - Adenine, Guanine, Cytosine, Thymine (and Uracil for RNA). Four organic molecules that provide the ‘coding region’ of DNA/RNA. Combinations of three nucleic acids are known as codons. The ribosome uses the codon during translation to pick the correct corresponding amino acid for building the polypeptide/protein.
Major Groove - When a strand of DNA is twisted into a double helix, the gaps between the chains of DNA backbone alternate between small and large. The larger gap is the major groove and it is considered to be richer in information, since the base pairs are sufficiently exposed to read without being broken apart. Both grooves surround the same sequence, the only difference is accessibility.
Melting Temperature (Tm) - The temperature at which exactly 50% of DNA is single stranded and 50% is double stranded. Higher GC content in a DNA sequence results in a higher melting temperature, higher AT content results in a lower melting temperature (3 hydrogen bonds vs. 2 hydrogen bonds). The Tm is a relevant factor when calculating the annealing temperature of primers for the Polymerase Chain Reaction.
Minor Groove - The smaller groove in the double-helix model of DNA.
Mitosis - Cellular division in eukaryotic organisms that results in 2 x 2n somatic daughter cells.
Meiosis - Cellular division in eukaryotic organisms that results in 4 x n gamete daughter cells.
Mutation - A change in the base pair sequence of DNA. Mutations in somatic cells will only affect the original organism, whereas mutations in the gametes or zygote will affect all future generations. Mutations can be caused by any number of possible carcinogenic influences, or introduced by pathogens.
Native State - DNA or proteins that are correctly folded and functional, as they would be in their natural environment.
Nitrogenous Base - Alkaline, nitrogen containing molecule that is a component of DNA. Two types, (purines and pyrimidines) appear in DNA as the molecules that provide the actual code (A, C, T, G + U in RNA).
Non-Homologous End-Joining (NHEJ) - If a double stranded break occurs in DNA and there is no nearby homologous region to act as a scaffold for repair, the cell will instead perform Non-Homologous End-Joining. The gap will be filled in with random bases and the backbone repaired. This can cause deleterious effects in any nearby gene sequences, and will likely inactivate any gene that it occurs within.
Nucleus - A membrane bound organelle in Eukaryotes that holds the genomic DNA. The nucleus is the command centre of the cell, but kept carefully isolated from the external environment to prevent external influences (e.g. Viruses) from interfering with the operation of the DNA. Once messenger RNA is transcribed and given a Cap and Tail, it leaves the nucleus for the Endoplasmic Reticulum, an organelle dedicated to translation. Here, Ribosomes translate the mRNA into protein. Prokaryotes do not have a nucleus, adopting a more laissez-faire approach with everything floating around in the cytoplasm.
Nuclear Membrane - A double layer of phospholipid membranes that encapsulates the nucleus of a cell. The outer layer of the outer membrane is partly combined with the Rough Endoplasmic Reticulum, simplifying the passage of mRNA molecules to the Ribosomes.
Nucleosides - A purine or a pyrimidine bound to a ribose sugar, but not to any phosphate.
Nucleotides - A purine or a pyrimidine bound to a ribose sugar and phosphate group. A ‘single unit’ of DNA. Can be an A, C, T or G.
Open Reading Frame (ORF) - A region of DNA/RNA that is translated. In order for this to occur it must be flanked by a Start and Stop Codon. There should also be a Ribosome Binding Site 6-8 base-pairs upstream to make the ORF functional.
Operon - A unit of interdependent gene sequences responsible for regulating a separate gene. Sometimes used to describe the regulatory apparatus of a gene as a whole, including any genes within the cluster. e.g. Lac Operon, Cumate Operon.
Oxidative - An oxidative environment is likely to induce oxidation, or the loss of electrons from any molecules contained within. Reductive species may be oxidative, as they induce oxidation in others. OILRIG = Oxidation is Loss, Reduction is Gain.
Parentage - The origin of daughter cells or a whole organism.
Periplasmic Space - Region between the inner and outer membrane in gram-negative bacteria. This is an oxidative environment that may be favourable to the folding of some proteins.
Phosphate - A phosphorous atom covalently bound to 4 oxygen atoms.
Plasmid - A circular structure of DNA capable of replicating independently from the rest of the genome.
Plasmid Supercoiling - A unique structural capability of circular DNA strands whereby the circle of DNA twists and writhes into a significantly smaller shape than would be possible with a linear DNA strand.
Polypeptide - A sequence of amino acids assembled in a continuous polypeptide chain.
Potency
Omnipotent/Totipotent - Can become any cell in the body, found in the fertilised egg (zygote).
Pluripotent - Can become any cell within a particular system, slightly more specialised. Found during foetal development.
Multipotent - Can become one of a small set of cell types within a particular system. Found during foetal development and in areas of a mature organism that require regular replenishment, e.g. bone marrow stem cells.
Unipotent - Specialised cells that can only divide to produce cells of the same type.
Primer - Short sequence of DNA, generally 15-40 base-pairs but can be shorter or longer. Used to ‘prime’ the Polymerase Chain Reaction by annealing during the annealing step and then providing a double stranded region for DNA Polymerase to bind.
Primer hairpin - Internal structure caused by self-association within the primer, rather than with the target sequence. Not good!
Promotion - The switching on or speeding up of genetic expression, either at the transcription or translation level. mRNA polymerase and associated transcription factors are recruited to a specific DNA sequence to encourage the production of a protein. A ‘promoter region’ upstream of a gene is responsible for recruiting the polymerase and transcription factors. Once transcribed, the promotion of protein translation may occur via chaperone proteins,
Protein - One or more polypeptide chains that have been folded to form a functional molecular machine. Read the Proteins101 guide for more information.
Protein-DNA/Protein-RNA complexes - A combination of proteins bound to DNA or RNA that creates a functional unit. These complexes are most often found within enzymes with a DNA/RNA related function, such as within Ribosomes or CRISPR/CAS9.
Proteome - The full sum of proteins that can be produced by a cell. Deeper analysis of the proteome can reveal quantitative insights into the levels of these proteins over time.
Prokaryotes - Organisms that lack membrane-bound organelles, with no nucleus to contain the genome. Most molecular machinery freely floats within the cytoplasm.
Quiescent - Cell that has entered the G0 resting state. Quiescent cells will not divide or work towards division until an appropriate signal is given.
Reductive - A reductive environment is likely to induce reduction, or the gain of electrons from any molecules contained within. Oxidative species may be reductive, as they induce reduction in others. OILRIG = Oxidation is Loss, Reduction is Gain.
Repression - The switching off or toning down of genetic expression, either at the transcription or translation level.
Reverse Mechanism - Runs in the 3’ > 5’ direction along DNA.
Ribose Sugar - C5H10O5 pentose sugar. Component in the DNA backbone.
Ribosome - A molecule consisting of RNA and proteins that is used by prokaryotes and eukaryotes alike to produce new proteins according to the code provided by a messenger RNA molecule. While there is some variation in the structure between species, ribosome are nearly ubiquitous across living organisms.
RNA - Ribonucleic Acid - a single chained molecule similar to DNA, although all the Thymines (T) are replaced with Uracils (U). RNA’s single chained nature allows it to form more complex 3-D shapes, resulting in a wide variety of uses. Messenger RNA is a molecule used to copy the code from DNA and move it to the Ribosome where it can be translated into protein. Read the RNA101 guide for more information!
Rough Endoplasmic Reticulum - An organelle in Eukaryotic organisms that contains the ribosomes necessary for protein production within an oxidative environment that helps facilitate the correct folding of the new protein.
Sexual Reproduction - The production of a new organism from the combination of gametes from two separate organisms into a new zygote.
Silencing RNAs - Regulation of genes by short stretches of RNA that inhibit specific processes by competitive binding.
Splicing - The recombination of exons after the removal of introns. Occasionally used as a verb for describing the cutting and pasting of DNA.
Start Codon - AUG, codes for Methionine. The first three base pair sequence (codon) in any translated DNA sequence.
Somatic - Relating to the body. Most often used to describe ‘somatic cells’ - cells that make up an individual but are not contributed to the next generation like germ-line cells.
Template Strand - Opposite the coding strand, the template strand is used for attaching the growing strand of mRNA produced by RNA polymerase. The template contains anti-codons, sequences that perfectly opposite sequences to the codons required for making a protein. A replaces T, C replaces G & vice versa.
Transcription/Transcribed - The conversion of DNA code into a messenger RNA molecule by the protein RNA Polymerase.
Transcription Factors - Proteins that assist the RNA polymerase as it binds and transcribes the mRNA strand from the template strand. Transcription factors generally speed up the process of transcription with their presence or slow it down by their absence.
Transcription Level - Regulation that occurs at or before the stage of transcription.
Transcriptome - The levels of mRNA produced at any one time within an organism. Due to the additional layer of translation regulation, the transcription levels may not necessarily be related to the levels of produced protein. Analysis of the changes in transcription levels in an organism over time and after changes in environmental pressures.
Translation/Translated - The conversion of the code on the messenger RNA molecule into a protein by a Ribosome. In Eukaryotes this occurs in the rough endoplasmic reticulum, in Prokaryotes this occurs in the cytoplasm.
Translational Level - Regulation that occurs at or before the stage of translation.
Upstream - In the 5’ direction from.
Virus - ‘Non-living’ agent that consists of DNA or RNA wrapped in a protein coat. Viruses inject their genome into a host cell. The intracellular machinery of the cell is hijacked for the purpose of making copies of the virus. Once no more room for viral particles is available, the outer membrane of the host is lysed and the viruses spill out to seek new targets.
Vesicles - Small compartment isolated from the rest of the cell or external environment by a phospholipid bilayer. Vesicles can ‘bud off’ larger membranes and are often used as vehicles for the transport of proteins, lipids or DNA.
Zygote - The first omnipotent/totipotent cell in a multicellular organism, often formed by the fertilisation of an egg by a sperm. Once fertilised, the zygote immediately begins dividing into multiple, more specialised cells.
Acknowledgements:
https://courses.lumenlearning.com/microbiology/chapter/protein-synthesis-translation/
https://www.philpoteducation.com/mod/book/view.php?id=802&chapterid=1073#/
https://ib.bioninja.com.au/standard-level/topic-3-genetics/33-meiosis/stages-of-meiosis.html
https://www.nature.com/scitable/topicpage/mitosis-and-cell-division-205/#
https://bmcgenomics.biomedcentral.com/articles/10.1186/s12864-019-5489-4